In our project (Writeslike.us) we are using a number of different techniques and tools to make things done.
Coding
As main development languages scripting languages Perl and Python were selected. Python is good for text parsing because language features and external library – Natural language toolkit (NLTK.org) which allow to stem and tag text. The text parsing is non-trivial tasks so for that purpose NLTK use heuristic approach and also offer a training data set for parser to be trained. Perl is native choice for development under Linux and it has powerful set of libraries in CPAN system. In particular XML parsing and full text document crawling functions were written in Perl.
As development tools we are using Eclipse IDE with Perl and Pydev for Perl and Python respectively. In some cases VIM featured text editor is in use. Using such heterogeneous tools implies that project file structure should be flat and simple.
Infrastructure
For running and hosting we are using such proven tools as MySQL and Apache. Subversion (SVN) is used to store and keep track of software versions.
Architecture
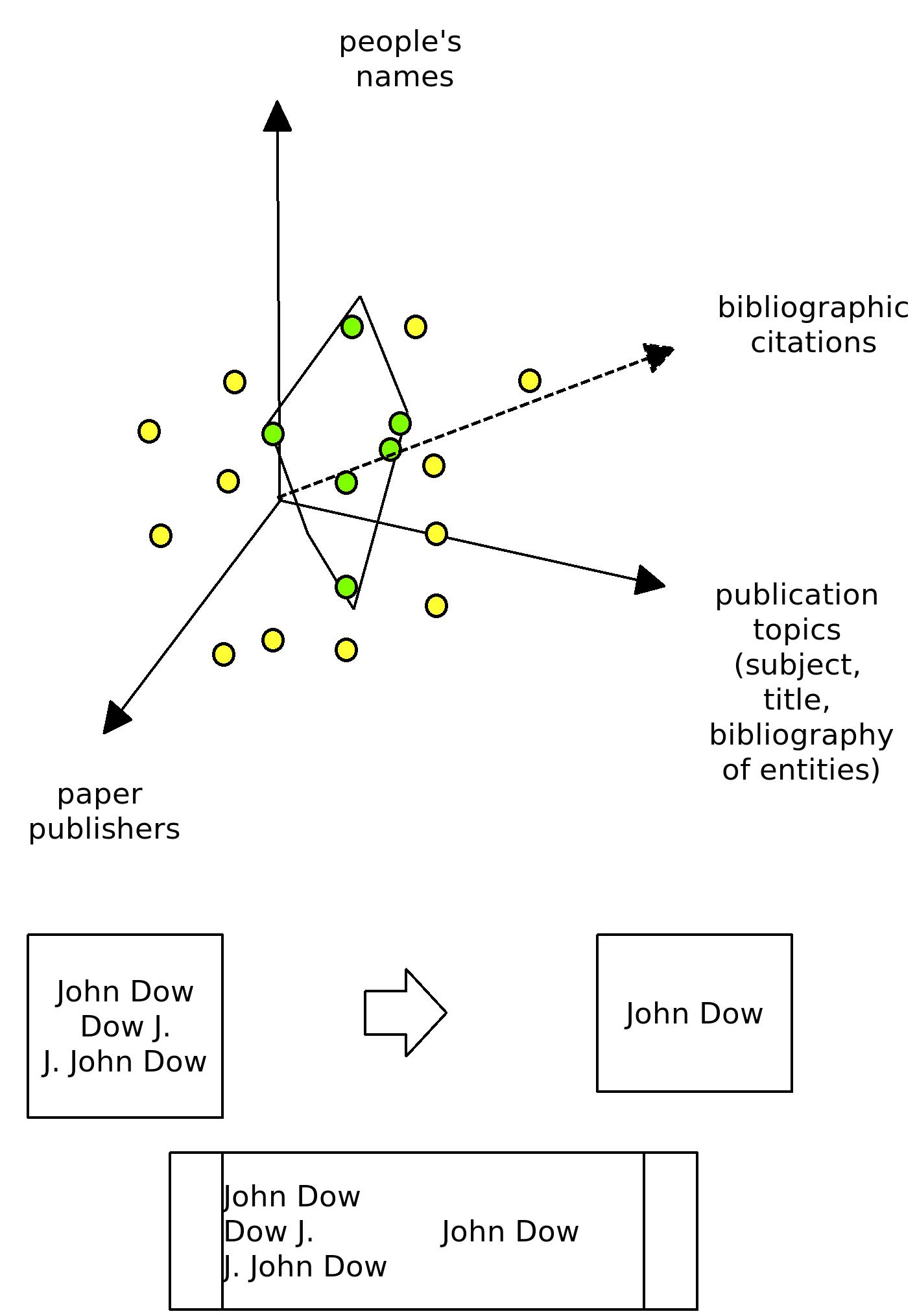
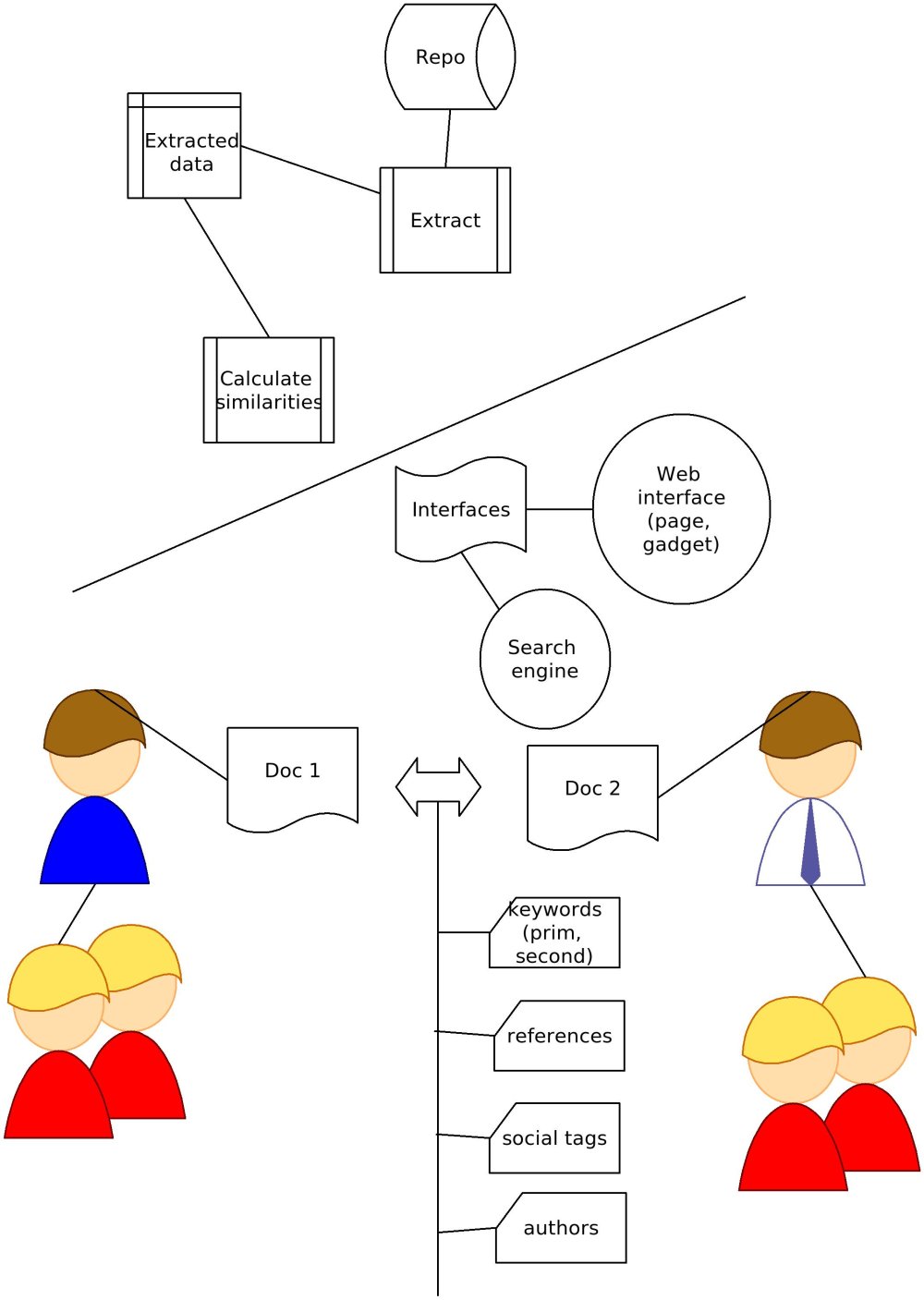
The calculation we need to perform to build authors relations network is too resource-intensive to be performed on demand, therefore we need to generated and store database tables with pre-calculated data as some sort of caching approach. Since our project is re-using existing metadata (in Dublin Core (oai-dc, often from qualified DC)) from a repository we were required to add to original project feature list also XML parser and document full text crawler functions.
In order increase usability of the project offered functionality we created a REST interface which enable machine2machine interface. The interface enabled in both directions, i.e. for adding new information about person or publication and for making query to find peers.
Further development plans adding automatic metadata extraction servers to improve quantity and quality of data or to extract further information (FixRep, paperBase).
What programming languages we use and why we love it/them -technologies, standards, frameworks that make our lives easier (or harder).
In actual fact there are rather a lot of these! In the case of writeslike.us we have stuck to scripting languages, in particular to Perl and Python. Each of these have their benefits and their issues. Arguments centre around Python’s semantic whitespace versus Perl’s line-noise pseudo-ppp transmission ‘write-once, read never’ look, for example. However, both come with a great variety of extensions and libraries. The ‘killer app’ for Python was NLTK, and once one is used to Perl’s CPAN, it becomes indispensable for certain tasks. In the end, arguing about which language is better is pointless, even though it is great fun. The Computer Science department presently teaches Python, and as such Python is the language with which most CS students are more familiar, whilst EE students seem to be either Perl or Matlab according to recent evidence.
In the end, the important point is that prototypes are developed quickly and easily, and that the techniques and datasets underlying them are well understood. If this is the case, then the rest can usually be adapted to suit – rapid development is not the same thing as throwaway prototyping, but rationalisation of software platforms and standards can very well be part of evolutionary prototype enhancement.