- Screenshots or diagram of prototype:

Searching for a person

Choosing an individual

Viewing information about them and people who ‘write like them’ -
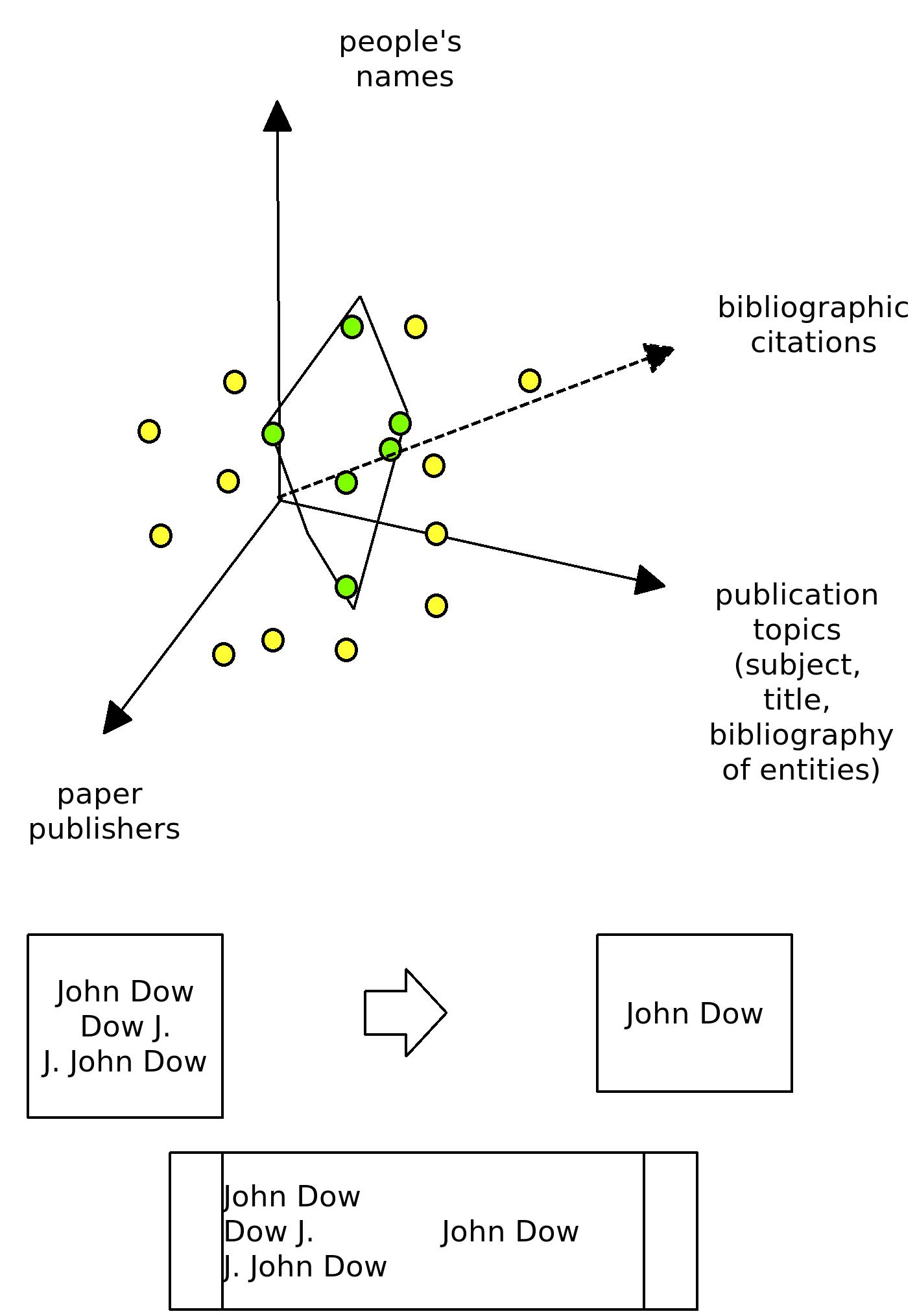
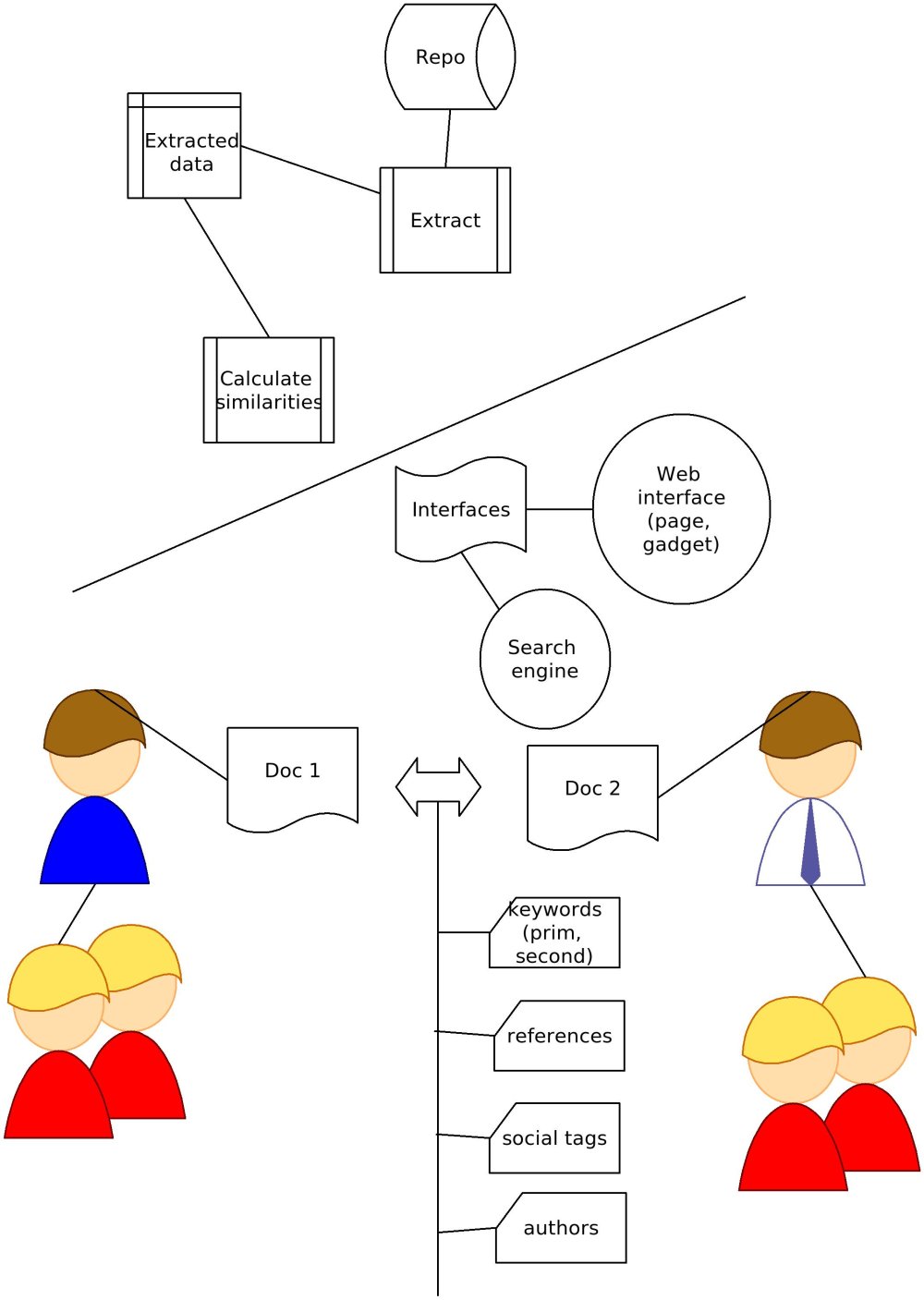
- Description of Prototype: Explore people, publications, institutions and themes through oai metadata
- End User of Prototype: “Jonathan is a researcher in evolutionary linguistics. He has become very interested in possible mathematical mechanisms for describing the nature, growth and adaption of language, as he has heard that others, such as Partha Nyogi, have done some very interesting work in this area. Unfortunately, Jonathan is not a mathematician and finds that some of the detail is hard to follow. He realises that what he really needs to do is either to go to the right sort of event or the right sort of online forum and find some people who might be interested in exploring links between his specialist area and their own. Both of these are difficult in their own ways. To go to the right sort of event would mean identifying what sort of event that would be, and he does not have enough money to go to very many. So he chooses to look up possible events and web forums, thinking that he can look through the participant lists for names that he recognises. This is greatly simplified by a system that uses information about the papers and authors that he considers most relevant; with this information it is able to parse through lists of participants in events or online communities in order to provide him with a rough classification of how relevant the group is likely to be to his ideas.”
- Link to working prototype: writeslike.us
- Link to end user documentation: http://www.ukoln.ac.uk/projects/writeslike.us
- Link to code repository or API: http://code.google.com/p/writeslikeus/
- Link to technical documentation: http://www.ukoln.ac.uk/projects/writeslike.us (TBA)
- Date prototype was launched: Dec 01 2009
- Project Team Names, Emails and Organisations: Emma Tonkin, e.tonkin@ukoln.ac.uk, UKOLN; Alexey Strelnikov, a.strelnikov@ukoln.ac.uk, UKOLN, Andrew Hewson, a.hewson@ukoln.ac.uk, UKOLN
- Project Website: http://code.google.com/p/writeslikeus/
- PIMS entry: https://pims.jisc.ac.uk/projects/view/1263
- Table of Content for Project Posts: TBA
writeslike.us: identity information from repository metadata
1 Reply