2 publications from one person - does it mean 2 people (with the same name) or it is one person?
The problem is unsolvable without additional information identifying the person. But for the case when this information is unavailable, there is a suggestion to apply pure statistics. In other words, evaluate for a testing (sample) data set what error level is linked to both possibilities – two different persons or one, just publishing in two places.
Then we switched to looking at practical methods to use within the Writeslike.us project, to identify individuals who write similarly or about similar topics.
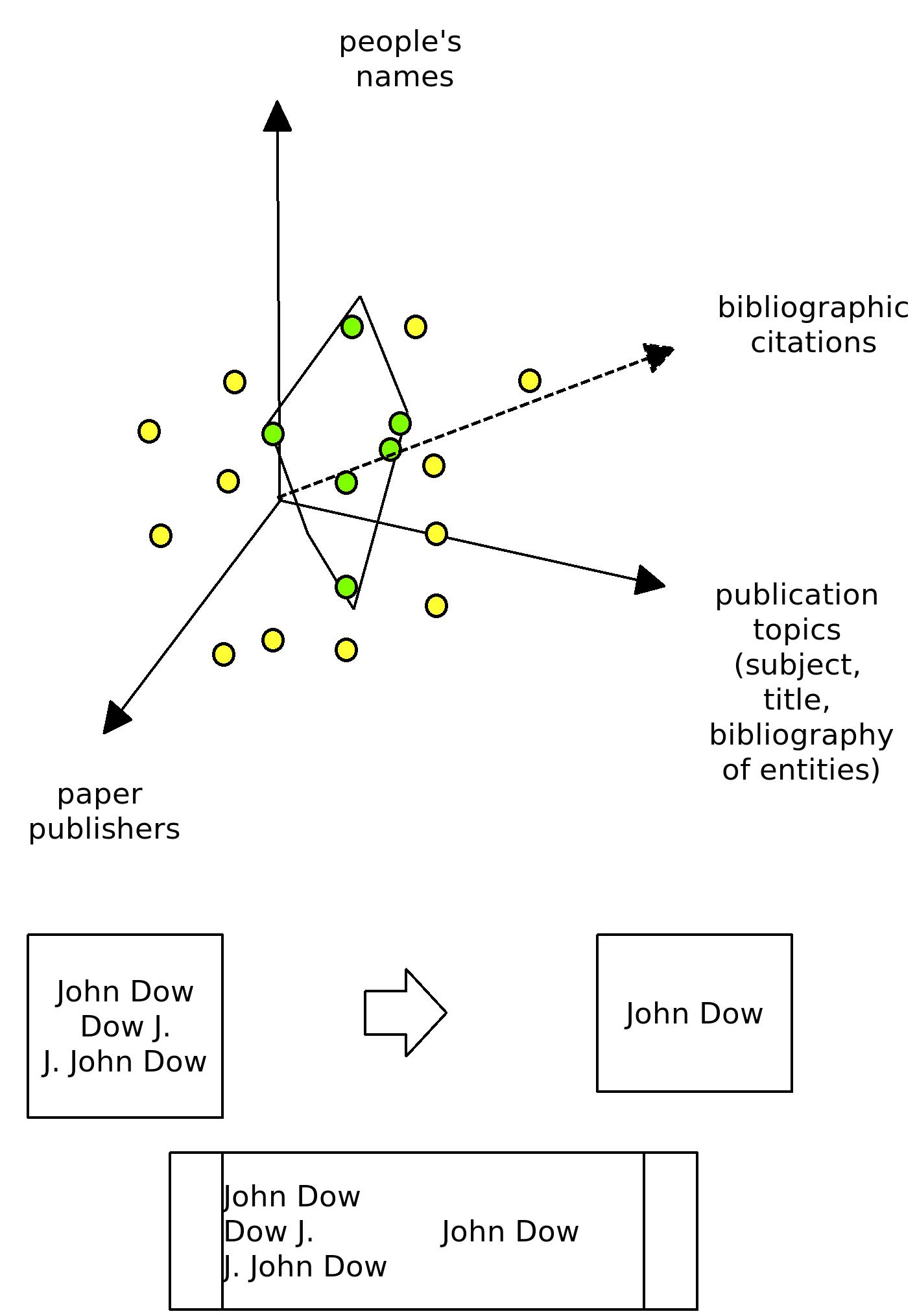
Person identity dimensions + table organization for mapping
This lovely diagram displays how the system we’re building will do the ‘magic’. Since none of the dimensions available to us are able to discriminate identity alone, we need to bring several onto the stage. The result will be an approximation incorporating evidence from several sources, which will hopefully make it more precise.
The table is just a representation of the way in which the heap of raw data will be mapped into something useful.